Date: 25 Apr, 2020
Few days back, I was in an unplanned call with Sanjiv. As the call wound up, I concluded my argument saying, “…after all, data is polysemous.” It was quite uncharacteristic that Sanjiv let me conclude that way because he has a nose for debatable ideas and data being labeled polysemous is at the least contentious.
Generally ‘polysemous’ refers to words with multiple meanings. But it’s not uncommon to use it to describe other things with multiple interpretations. For example, is Da Vinci’s Mona Lisa smiling or is she stoic? However, can the same be said about data? Is it really polysemous?
Nobel laureate economist Ronald Coase remarked, “If you torture the data long enough, it will confess to anything.” This and other similar statements have been used to argue how the same data set can provide multiple conflicting insights. But, is that because data is polysemous or is the lack of supporting data making the available data open to interpretation? Of course it is the latter. Let us look at an example. With COVID-19, companies are sitting on piles of unsold stocks. Ask the warehouse guy and he will blame the virus. The manager may point out that the pileup was there before the pandemic set in. Both probably have valid points. Splitting the blame ‘fairly’ between the virus and human requires more data – orders, returns, cancellations and production/ purchases… before and after the pandemic broke out.
It is interesting that a simple question about excess inventory can touch data from virtually every “module” of day-to-day operations. You cannot solve the issues in one area of operations by being oblivious of the others. Trying to do that will need assumptions. And debates around such assumptions has given data the polysemous label.
The trend of using IT to solve the problem of connectedness between departments started with ERP becoming popular in the early 90s. Since then many IT projects owe their sponsorship to replicating such real-world connections into enterprise systems.
However, of late Point-Solutions are making a comeback. This seeming reversal of the three decade trend is enabled by the ubiquity of data lakes and the mushrooming of many cloud based narrow focused solutions. Data lakes make it easier to provision subsets of data to these applications. For functional leaders, it is a quick way to solve a nagging problem. For IT, it speeds up delivery.
This is great for many enterprise applications not directly linked to the larger operations. Examples include leave administration, benefits management and travel reimbursement. But, for operations such applications can be a poisoned chalice. It may offer a short term fix. But, operational problems evolve over time, and soon the trickle from the data lake will be found insufficient. And managers will be forced to work with conjectures plunging them back into the polysemous data problem.
What is the solution? Simple… ensure that solutions meant for core operational areas not only address the current problem in depth but also have sufficient breadth to make them future proof. At a minimum, the solution should be able to ingest and consume the wide swathe of enterprise data in a meaningful way. For example, today an inventory manager might want to be alerted to slow moving, obsolete or about to expire goods. A solution using sophisticated algorithms to compare forecasts and customer orders, to inventory should work. But, in a few months, the problem may expand from inventory liquidation to profit maximization, and additional data points from customer price sensitivity to logistics costs will be needed. And in a year, supply might have to be factored in for cancelations and returns. If the platform is already bringing in all the data and has analytical capabilities, enriching the application as the process evolves is a breeze. However, if the required data is not there, the limits of the application will be apparent. Soon, the polysemous data problem will set in, and the enterprise will be back hunting for another application that will address the latest problem statement!
This thought process has driven the development of OpsVeda AiO (All-in-One). Interconnectedness of supply chain functions means that data from across the supply chain – Fulfillment, Revenue Management, Inventory and Logistics – is brought in to solve problems comprehensively even if the problem is a priority for only one department for now. The cross functional data and inbuilt tools allow users to get the required context when addressing the problem. This approach also allows the solution scope to keep pace with changing business practices. The time to delivery is very comparable to the narrow focused solutions because of the ease of development enabled by the platform and the rich catalogue of pre-built content. But that is an old story – a 6-8 week go-live has always been OpsVeda’s strength!
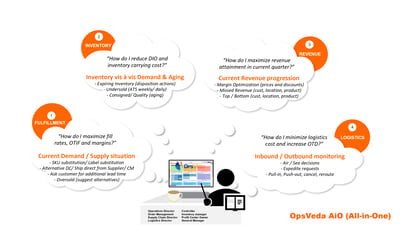
Do you often hear from your colleagues about data being polysemous? It’s not data but the lack of it that is polysemous! Fix it once and for all. Get a 360O view of the problem and solve the same for broader company objectives rather than to satisfy narrow departmental priorities. Ask us about OpsVeda AiO to know how.